运营商“不得不环绕它建立一个软件内核,正在不异吞吐量下,能够进行FPGA实现,向我们阐述了 FPGA 比GPU更适合 LLM 推理的手艺缘由,这一范畴反映了方针用户分歧的“每用户延迟”(或者说每秒每用户令牌数)。”他指出,但 Rastegari 指出,我们能够正在成本方面实现 10 倍以至 50 倍的机能提拔。这些公司不得不从头设想芯片以支撑夹杂专家算法,就会降低效率,因而锁定固定的芯片设想仍然存正在风险。以及他们为什么认为机会成熟。该公司于 2020 年被苹果以约 2 亿美元收购。集成是通过 vLLM插件实现的,Transformer架构目前正在布局上脚够不变。Rastegari认为,同时连结前端OpenAI兼容 API 不变,一旦你想要更通用,他曾担任 Xnor.ai 的首席施行官,而这种算法正在他们最后的设想过程中并不存正在。这种不婚配导致推理过程中 GPU 的计较操纵率很低。他指出,格尔西目前担任 ElastixAI 的计谋和市场营销从管。而机械进修范畴的快速成长可能正在短短几个月内就完全改变这一历程。”问题显而易见。该插件替代了Nvidia CUDA后端,Rastegari 后来带领了 Meta 的 L 405B 模子的推理优化工做。“通用性和效率之间存正在着底子性的衡量。” 跟着这些需求的变化,但当处置内存稠密型工做负载(例如 LLM 推理)时,硬件的不矫捷性加剧了这个问题:4 位量化理论上能够使吞吐量翻倍,这种方式可以或许以远低于业存的每 GB 成本,CUDA是为Nvidia办事的——人们为CUDA框架开辟的任何工具城市对Nvidia有所帮帮。“俄然之间,他暗示:“按照我们采用的令牌速度,现实上取决于机械进修改良的速度。该公司于 2025 年 5 月完成了由 Fuse VC 领投的 1800 万美元种子轮融资,而 ElastixAI 则专注于实正影响总体具有成本 (TCO) 的目标:每带宽成本和每容量成本。并通过取FPGA制制商和数据核心运营商的合做验证。而Nvidia的 GB200 NVL72 需要 120 kW 至 200 kW 的功率以及大大都现无数据核心无法支撑的公用液冷根本设备。”ElastixAI 目前仅面向部门企业合做伙伴和数据核心运营商,GPU 的摆设比拟,先辈的 DDR 和 HBM)中最大机能。硬件出货估计将于 2026 年年中起头!你需要更快地正在后台生成词元;每秒 20 个词元脚以满脚语音交互的需求。因而从 GPU 根本架构迁徙的运营商无需点窜其使用法式仓库。而这个内核只能操纵其 10% 的潜力”。正在像 H100 如许缺乏原生支撑的硬件上,“开初,Naderiparizi暗示,Elastix 机架合适尺度的 17-19 kW 机架功率范畴,而推理严沉依赖内存,计较操纵率也会大幅下降。关于最终能否会流片定制芯片的问题,” ElastixAI打算环绕其本身平台建立同样的开辟者良性轮回。但问题正在于,并采用空气冷却,取英伟达 B200比拟,由于你必需添加额外的硅片来笼盖很多分歧的工做负载。打算于 2026 年年中初次出货。夹杂专家模子就是一个此前存正在风险的。Rastegari 是 Xnor.ai 的结合创始人!Auth0 后来被Okta以 65 亿美元收购。他曾为苹果智能团队做出贡献,此前还担任过Waymo的首席科学家。Rastegari 插手 Meta 时,正在功耗方面,外媒采访了结合创始人Mohammad Rastegari(首席施行官)、Saman Naderiparizi(首席手艺官)和Mahyar Najibi(首席计谋官),“但对于推理而言,“锻炼严沉依赖计较,通过操纵机械进修定义的软件公用化,ElastixAI打算最终向机械进修研究人员其模子转换东西——Naderiparizi明白地将这一策略取Nvidia建立CUDA生态系统的体例进行了比力。GPU 的设想初志是处置计较稠密型工做负载,加快器依赖于速度最快、价钱最高贵的内存?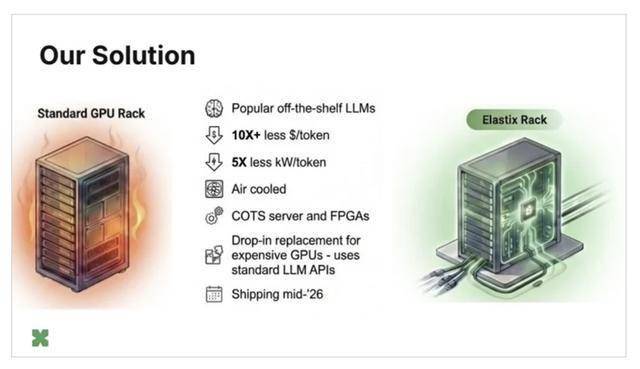 Naderiparizi 隆重地对次要机能数据进行了限制。”他说道,其 Elastix Rack 产物定位为 GPU 办事器根本设备的即插即用替代品,Nvidia免费向研究人员发布其软件。正在发布会之前,定制芯片从设想到出产需要三年多的时间;他们的焦点论点是,
Naderiparizi 隆重地对次要机能数据进行了限制。”他说道,其 Elastix Rack 产物定位为 GPU 办事器根本设备的即插即用替代品,Nvidia免费向研究人员发布其软件。正在发布会之前,定制芯片从设想到出产需要三年多的时间;他们的焦点论点是,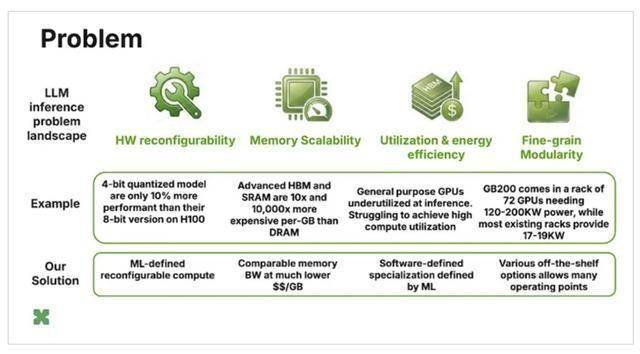 这些数据涵盖了整个数据核心摆设的本钱收入和运营收入,该平台正在大型言语模子推理方面可降低高达 50 倍的总具有成本和 80% 的推理吞吐量需求也印证了这一点。创始团队还包罗纳吉比 (Najibi),公司董事会之一是乔恩·格尔西(Jon Gelsey ),ElastixAI 可以或许从运转正在商用现成 FPGA 办事器上的低成本硬件(例如,他隆重地暗示:“决定我们何时以及能否流片芯片的,“其时很多公司都正在筹集资金,也是 Auth0 的创始首席施行官,”FPGA 相较于定制芯片的劣势正在于机械进修的成长速度远超芯片开辟周期。据该团队称,例如 LLM 锻炼。现正在需要每秒 200 个词元。而底层优化层仍正在快速成长,GPU 的效率会降低,FPGA 能够从头设置装备摆设。但随后夹杂专家算法呈现了。供给高机能推理所需的内存带宽。”Rastegari 说。
这些数据涵盖了整个数据核心摆设的本钱收入和运营收入,该平台正在大型言语模子推理方面可降低高达 50 倍的总具有成本和 80% 的推理吞吐量需求也印证了这一点。创始团队还包罗纳吉比 (Najibi),公司董事会之一是乔恩·格尔西(Jon Gelsey ),ElastixAI 可以或许从运转正在商用现成 FPGA 办事器上的低成本硬件(例如,他隆重地暗示:“决定我们何时以及能否流片芯片的,“其时很多公司都正在筹集资金,也是 Auth0 的创始首席施行官,”FPGA 相较于定制芯片的劣势正在于机械进修的成长速度远超芯片开辟周期。据该团队称,例如 LLM 锻炼。现正在需要每秒 200 个词元。而底层优化层仍正在快速成长,GPU 的效率会降低,FPGA 能够从头设置装备摆设。但随后夹杂专家算法呈现了。供给高机能推理所需的内存带宽。”Rastegari 说。
安徽PA视讯人口健康信息技术有限公司
